It's been a while since I wrote a casual article. I should write something for the first article of the new year to complete my OKR. Recently, I helped a friend in the group investigate a special No space left on device issue, so I’ll document it.
Issue#
In the middle of the night, I received a request for help from a friend in the group, saying that their testing environment encountered some problems. Since I was still awake, I decided to take a look.
The situation of the problem is quite simple:
Using
docker run -d --env-file .oss_env --mount type=bind,src=/data1,dst=/cache {image}to start a container, and then found that after starting, the business code reported an error, throwing OSError: [Errno 28] No space left on device exception.
This problem is actually quite typical, but the final result of the investigation was indeed atypical. However, the investigation process should be a typical step-by-step analysis of the root cause of an online issue. I hope it can help the readers.
Investigation#
First, my friend provided the first key piece of information: there was space available, but still OSError: [Errno 28] No space left on device. So, for those familiar with Linux, the first step in the investigation might be to check the corresponding inode situation.
Execute the command:
df -ih
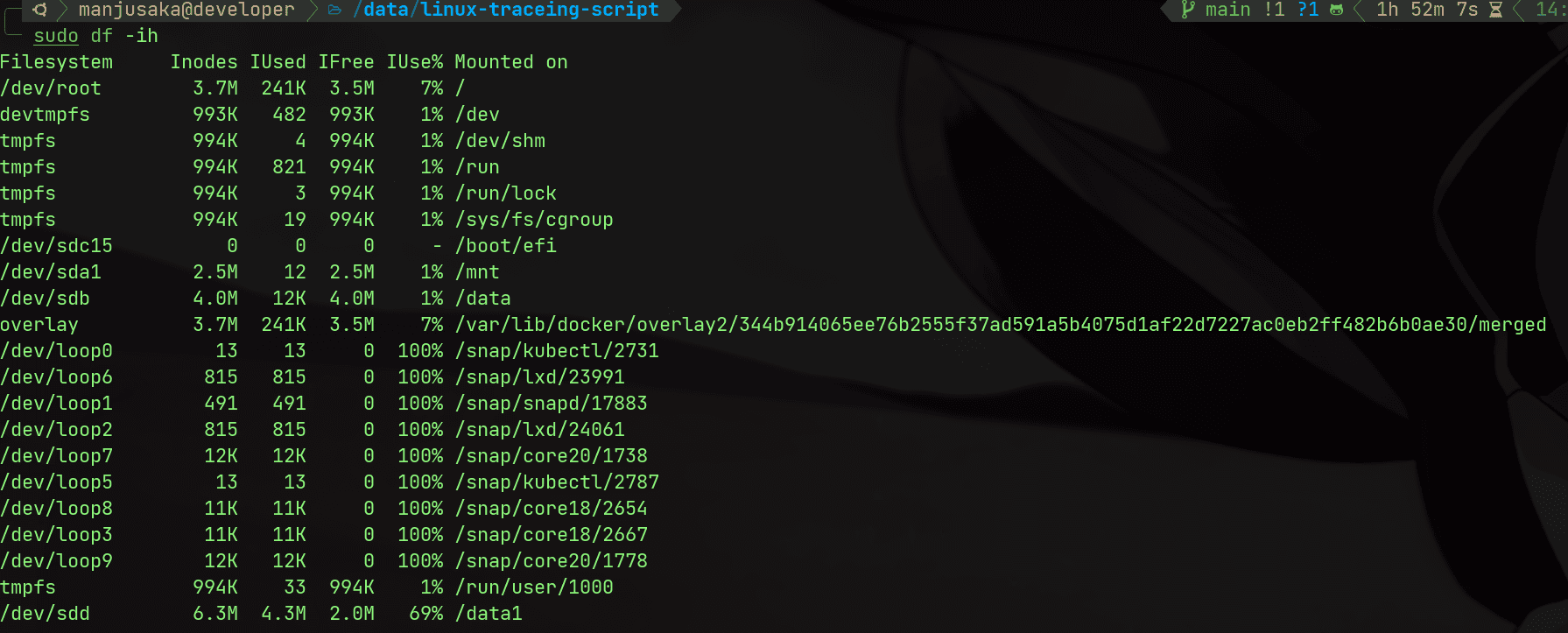
We can see that the inode count for /data1 and the total inode count on the machine are both sufficient (Note: This is a screenshot I took while reproducing the issue on my own machine; the first step was completed by my friend, who then provided me with the information).
Next, we continue the investigation. We noticed that we used mount bind1 to mount the host's /data1 to the container's /cache directory. The difference between mount bind and volume can be illustrated with the following image:

On different kernel versions, the behavior of mount bind has some special cases, so we need to confirm whether the mount bind situation is correct. We use fallocate2 to create a 1G file and then check the file size inside the container.
fallocate -l 10G /cache/test
The file creation went smoothly, so we can rule out any defects with mount bind.
Next, my friend mentioned that this disk is a cloud disk from a cloud vendor (after expansion). I asked my friend to confirm whether it was a specific ESSD or a NAS-type block device mounted via NFS (which also has its pitfalls). After confirming it was a standard ESSD, we moved on to the next step (we can rule out driver issues for now).
Next, we need to consider the issues with mount --bind in cross-filesystem situations. Although we successfully created a file in the previous step, to be safe, we executed the commands fdisk -l and tune2fs -l to confirm the correctness of the partition and filesystem. We confirmed that the filesystem type is ext4, so there are no issues. For the specific usage of the two commands, refer to fdisk3 and tune2fs4.
Then, recalling that we had no issues creating directly under /cache, we should have a rough idea that this is likely not a code issue or a permissions issue (in this step, I additionally ruled out that there were no extra user operations in the image build). So, we need to rule out any issues related to the expansion. After unmounting /data1 and remounting it, we executed the container again and found that the problem still existed, allowing us to rule out expansion issues.
Now that some common problems have been basically ruled out, we need to consider issues with the filesystem itself. I logged into the machine and performed the following two operations:
- In the problematic directory
/cache/xxx/, I created a file (with a long filename) usingfallocate -l, which failed. - In the problematic directory
/cache/xxx/, I created a file (with a short filename) usingfallocate -l, which succeeded.
OK, we are now leaning towards filesystem anomalies in our investigation. We executed the command dmesg5 to check the kernel logs and found the following errors:
[13155344.231942] EXT4-fs warning (device sdd): ext4_dx_add_entry:2461: Directory (ino: 3145729) index full, reach max htree level :2
[13155344.231944] EXT4-fs warning (device sdd): ext4_dx_add_entry:2465: Large directory feature is not enabled on this filesystem
OK, we found the expected exception information. The reason is that the BTree index used by ext4, by default, only allows a tree height of 2, which effectively limits the number of files in a directory to about 2k-3k. After confirmation, there were indeed a large number of small files in the problematic directory. We then used tune2fs -l to confirm whether it was as we suspected and obtained the result:
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
Bingo, the large_dir option was indeed not enabled. We then executed tune2fs -O large_dir /dev/sdd to enable this option and confirmed it was enabled by executing tune2fs -l again. We then executed the container once more and found that the problem was resolved.
Verification#
The investigation of the above issue seems to have reached a conclusion. However, it is not truly closed-loop. A closed-loop for a problem has two characteristics:
- Locating the specific exception code.
- Having a minimal reproducible version to confirm that the root cause we found is as expected.
From the above dmesg information, we can locate the function in the kernel, which is implemented as follows:
static int ext4_dx_add_entry(handle_t *handle, struct ext4_filename *fname,
struct inode *dir, struct inode *inode)
{
struct dx_frame frames[EXT4_HTREE_LEVEL], *frame;
struct dx_entry *entries, *at;
struct buffer_head *bh;
struct super_block *sb = dir->i_sb;
struct ext4_dir_entry_2 *de;
int restart;
int err;
again:
restart = 0;
frame = dx_probe(fname, dir, NULL, frames);
if (IS_ERR(frame))
return PTR_ERR(frame);
entries = frame->entries;
at = frame->at;
bh = ext4_read_dirblock(dir, dx_get_block(frame->at), DIRENT_HTREE);
if (IS_ERR(bh)) {
err = PTR_ERR(bh);
bh = NULL;
goto cleanup;
}
BUFFER_TRACE(bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, bh, EXT4_JTR_NONE);
if (err)
goto journal_error;
err = add_dirent_to_buf(handle, fname, dir, inode, NULL, bh);
if (err != -ENOSPC)
goto cleanup;
err = 0;
/* Block full, should compress but for now just split */
dxtrace(printk(KERN_DEBUG "using %u of %u node entries\n",
dx_get_count(entries), dx_get_limit(entries)));
/* Need to split index? */
if (dx_get_count(entries) == dx_get_limit(entries)) {
ext4_lblk_t newblock;
int levels = frame - frames + 1;
unsigned int icount;
int add_level = 1;
struct dx_entry *entries2;
struct dx_node *node2;
struct buffer_head *bh2;
while (frame > frames) {
if (dx_get_count((frame - 1)->entries) <
dx_get_limit((frame - 1)->entries)) {
add_level = 0;
break;
}
frame--; /* split higher index block */
at = frame->at;
entries = frame->entries;
restart = 1;
}
if (add_level && levels == ext4_dir_htree_level(sb)) {
ext4_warning(sb, "Directory (ino: %lu) index full, "
"reach max htree level :%d",
dir->i_ino, levels);
if (ext4_dir_htree_level(sb) < EXT4_HTREE_LEVEL) {
ext4_warning(sb, "Large directory feature is "
"not enabled on this "
"filesystem");
}
err = -ENOSPC;
goto cleanup;
}
icount = dx_get_count(entries);
bh2 = ext4_append(handle, dir, &newblock);
if (IS_ERR(bh2)) {
err = PTR_ERR(bh2);
goto cleanup;
}
node2 = (struct dx_node *)(bh2->b_data);
entries2 = node2->entries;
memset(&node2->fake, 0, sizeof(struct fake_dirent));
node2->fake.rec_len = ext4_rec_len_to_disk(sb->s_blocksize,
sb->s_blocksize);
BUFFER_TRACE(frame->bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, frame->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
if (!add_level) {
unsigned icount1 = icount/2, icount2 = icount - icount1;
unsigned hash2 = dx_get_hash(entries + icount1);
dxtrace(printk(KERN_DEBUG "Split index %i/%i\n",
icount1, icount2));
BUFFER_TRACE(frame->bh, "get_write_access"); /* index root */
err = ext4_journal_get_write_access(handle, sb,
(frame - 1)->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
memcpy((char *) entries2, (char *) (entries + icount1),
icount2 * sizeof(struct dx_entry));
dx_set_count(entries, icount1);
dx_set_count(entries2, icount2);
dx_set_limit(entries2, dx_node_limit(dir));
/* Which index block gets the new entry? */
if (at - entries >= icount1) {
frame->at = at - entries - icount1 + entries2;
frame->entries = entries = entries2;
swap(frame->bh, bh2);
}
dx_insert_block((frame - 1), hash2, newblock);
dxtrace(dx_show_index("node", frame->entries));
dxtrace(dx_show_index("node",
((struct dx_node *) bh2->b_data)->entries));
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
if (err)
goto journal_error;
brelse (bh2);
err = ext4_handle_dirty_dx_node(handle, dir,
(frame - 1)->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir,
frame->bh);
if (restart || err)
goto journal_error;
} else {
struct dx_root *dxroot;
memcpy((char *) entries2, (char *) entries,
icount * sizeof(struct dx_entry));
dx_set_limit(entries2, dx_node_limit(dir));
/* Set up root */
dx_set_count(entries, 1);
dx_set_block(entries + 0, newblock);
dxroot = (struct dx_root *)frames[0].bh->b_data;
dxroot->info.indirect_levels += 1;
dxtrace(printk(KERN_DEBUG
"Creating %d level index...\n",
dxroot->info.indirect_levels));
err = ext4_handle_dirty_dx_node(handle, dir, frame->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
brelse(bh2);
restart = 1;
goto journal_error;
}
}
de = do_split(handle, dir, &bh, frame, &fname->hinfo);
if (IS_ERR(de)) {
err = PTR_ERR(de);
goto cleanup;
}
err = add_dirent_to_buf(handle, fname, dir, inode, de, bh);
goto cleanup;
journal_error:
ext4_std_error(dir->i_sb, err); /* this is a no-op if err == 0 */
cleanup:
brelse(bh);
dx_release(frames);
/* @restart is true means htree-path has been changed, we need to
* repeat dx_probe() to find out valid htree-path
*/
if (restart && err == 0)
goto again;
return err;
}
The main function of the ext4_dx_add_entry function is to add a new directory entry to the directory index. We can see that this function checks whether the corresponding feature is enabled and the current BTree height at add_level && levels == ext4_dir_htree_level(sb). If it exceeds the limit, it returns ENOSPC, which is ERROR 28.
Now, before reproducing the exception, let's get the call path of this function. I used eBPF tracing to obtain the stack trace, and since it is unrelated to the main body, I won't include the code here.
ext4_dx_add_entry
ext4_add_nondir
ext4_create
path_openat
do_filp_open
do_sys_openat2
do_sys_open
__x64_sys_openat
do_syscall_64
entry_SYSCALL_64_after_hwframe
[unknown]
[unknown]
So how do we verify that this is our exception?
First, we use eBPF + kretprobe to obtain the return value of ext4_dx_add_entry. If the return value is ENOSPC, we can confirm that this is our exception.
The code is as follows (don't ask me why I didn't write this in Python; I had to write it in C):
from bcc import BPF
bpf_text = """
#include <uapi/linux/ptrace.h>
BPF_RINGBUF_OUTPUT(events, 65536);
struct event_data_t {
u32 pid;
};
int trace_ext4_dx_add_entry_return(struct pt_regs *ctx) {
int ret = PT_REGS_RC(ctx);
if (ret == 0) {
return 0;
}
u32 pid=bpf_get_current_pid_tgid()>>32;
struct event_data_t *event_data = events.ringbuf_reserve(sizeof(struct event_data_t));
if (!event_data) {
return 0;
}
event_data->pid = pid;
events.ringbuf_submit(event_data, sizeof(event_data));
return 0;
}
"""
bpf = BPF(text=bpf_text)
bpf.attach_kretprobe(event="ext4_dx_add_entry", fn_name="trace_ext4_dx_add_entry_return")
def process_event_data(cpu, data, size):
event = bpf["events"].event(data)
print(f"Process {event.pid} ext4 failed")
bpf["events"].open_ring_buffer(process_event_data)
while True:
try:
bpf.ring_buffer_consume()
except KeyboardInterrupt:
exit()
Then we write a very short Python script:
import uuid
import os
for i in range(200000000):
if i % 100000 == 0:
print(f"we have created {i} files")
filename=str(uuid.uuid4())
file_name=f"/data1/cache/{filename}+{filename}.txt"
with open(file_name, "w+") as f:
f.write("")
Then we see the execution result:

This is as expected, so we can say that the causal chain of the investigation path for this problem is complete. We can officially declare that this issue has been resolved.
As a bonus, for such upstream issues, it would be even better if we could find out exactly when the fix was made. In this case, the large_dir feature for ext4 was introduced in Linux 4.13, as can be seen in 88a399955a97fe58ddb2a46ca5d988caedac731b6 commit.
OK, this issue is settled.
Summary#
This issue is relatively niche, but the investigation method is actually quite typical for online problem investigation. For problems, do not make assumptions about the results; step by step, approach the final conclusion based on the phenomena. Also, eBPF is really a great tool that can help with many kernel-related tasks. Lastly, my foundation in Linux filesystems is still too weak, and I hope to strengthen it in the future.
That's about it.