今週、友人のために eBPF/SystemTap のような動的 tracing ツールを使っていくつかの非常に興味深い機能を実装しました。この記事はそのまとめです。
はじめに#
実際、今週のいくつかのアイデアは、ある日友人から私に尋ねられた質問に由来しています。
私たちは、マシン上でどのプロセスが ICMP リクエストを発信しているかを監視できますか?PID、ICMP パケットの出口アドレス、ターゲットアドレス、プロセスの起動コマンドを取得する必要があります。
非常に興味深い質問です。実際、この問題を受けたとき、私たちの第一反応は「マシン上のプロセスが ICMP パケットを発信するときに、直接どこかにログを書き込むのが良いのでは?」というものでした。emmmm、meme で盛り上げましょう。

うん、みんなが私が言いたいことを理解しているかもしれませんが、私たちのようなシナリオでは、実際にはバイパス、非侵入的な方法を選択するしかありません。
パケットのバイパストレースに関しては、みんなの第一反応は必ず tcpdump でパケットをキャプチャすることです。しかし、今日の問題において、tcpdump はパケット情報を取得することはできますが、具体的な PID や起動コマンドなどの情報は取得できません。
したがって、私たちは別の方法を使って私たちのニーズを実現する必要があります。
ニーズの最初の段階では、私たちが選択できる方法はいくつかありました。
- /proc/net/tcp を通じて具体的なソケットの inode 情報を取得し、PID を逆引きする。
- eBPF + kprobe を使用してカーネルのモニタリングを行う。
- SystemTap + kprobe を使用してカーネルのモニタリングを行う。
最初の方法では、実際には TCP 層の情報しか取得できませんが、ICMP は TCP プロトコルではありません(残念ながら、同じ L4 に属しています)。
最終的に、私たちは eBPF/SystemTap と kprobe を組み合わせた唯一の道を選ぶことになりました。
基本的なトレース#
Kprobe#
次のコードの実際の操作に進む前に、まず Kprobe について理解しておく必要があります。
まず、公式文書の紹介を引用します。
Kprobes は、任意のカーネルルーチンに動的に割り込んで、デバッグおよびパフォーマンス情報を非破壊的に収集できるようにします。ブレークポイントがヒットしたときに呼び出されるハンドラールーチンを指定して、ほぼ任意のカーネルコードアドレスでトラップできます。
現在、2 種類のプローブがあります:kprobes と kretprobes(リターンプローブとも呼ばれます)。kprobe は、カーネル内のほぼ任意の命令に挿入できます。リターンプローブは、指定された関数が戻るときに発火します。
一般的な場合、Kprobes ベースの計装はカーネルモジュールとしてパッケージ化されます。モジュールの初期化関数は、1 つ以上のプローブをインストール(「登録」)し、終了関数はそれらを登録解除します。register_kprobe () のような登録関数は、プローブを挿入する場所と、プローブがヒットしたときに呼び出されるハンドラを指定します。
簡単に言えば、kprobe はカーネルが提供するトレースメカニズムであり、特定のカーネル関数を実行する際に、私たちが設定したルールに従ってコールバック関数をトリガーします。公式の言葉を借りれば、「ほぼ任意のカーネルコードアドレスでトラップできます」。
今日のシナリオでは、eBPF を利用するにせよ SystemTap を利用するにせよ、Kprobe に依存し、適切なフックポイントを選択してカーネル呼び出しのトレースを完了する必要があります。
では、今日のシナリオでは、どの関数に対応するフックを追加すべきでしょうか?
まず考えてみましょう。ICMP は L4 パケットであり、最終的には IP パケットにカプセル化されて配信されます。では、カーネル内の IP パケット送信における重要な呼び出しを見てみましょう。以下の図を参照してください。
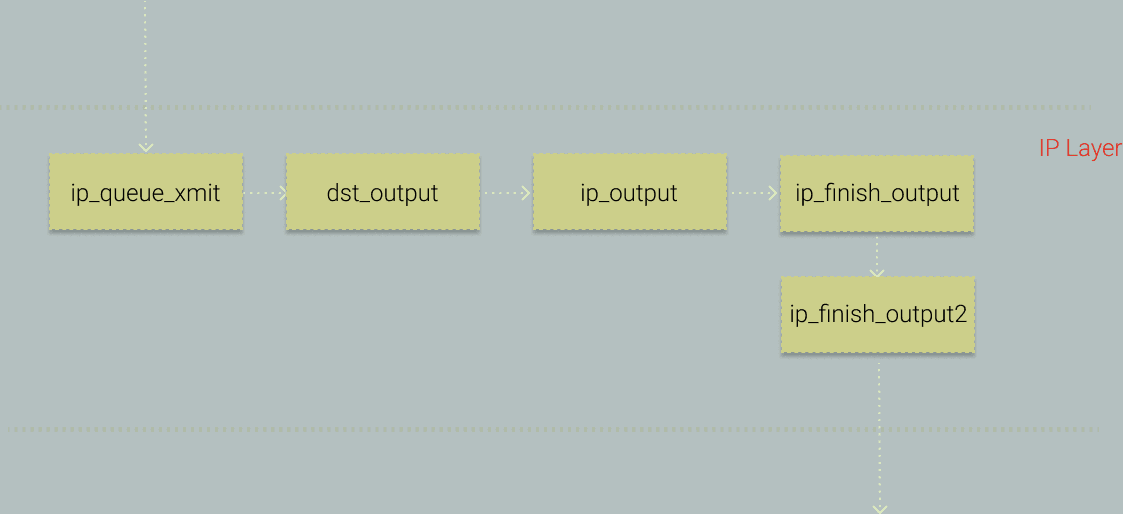
ここで、ip_finish_output をフックポイントとして選択します。
OK、フックポイントが確認されたので、正式にコーディングを始める前に、ip_finish_output について簡単に紹介します。
ip_finish_output#
まず、この関数を見てみましょう。
static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int ret;
ret = BPF_CGROUP_RUN_PROG_INET_EGRESS(sk, skb);
switch (ret) {
case NET_XMIT_SUCCESS:
return __ip_finish_output(net, sk, skb);
case NET_XMIT_CN:
return __ip_finish_output(net, sk, skb) ? : ret;
default:
kfree_skb(skb);
return ret;
}
}
具体的な詳細はここでは展開しません(実際には非常に多いので Orz)。システムコール ip_finish_output が呼び出されると、私たちが設定した kprobe のフックがトリガーされ、私たちが設定したフック関数に net, sk, skb の 3 つのパラメータが渡されます(これらの 3 つのパラメータは ip_finish_output を呼び出すときの値です)。
この 3 つのパラメータの中で、主に struct sk_buff *skb に注目します。
Linux カーネルのプロトコルスタックの実装に精通している方は、sk_buff というデータ構造に非常に馴染みがあるでしょう。このデータ構造は、Linux カーネルにおけるネットワーク関連のコアデータ構造です。ポインタのオフセットを使って、このデータ構造は、送信待ち / 受信済みのデータがメモリ内にどこに格納されているかを簡単に確認するのに役立ちます。
言葉で説明するのは少し抽象的なので、図を見てみましょう。
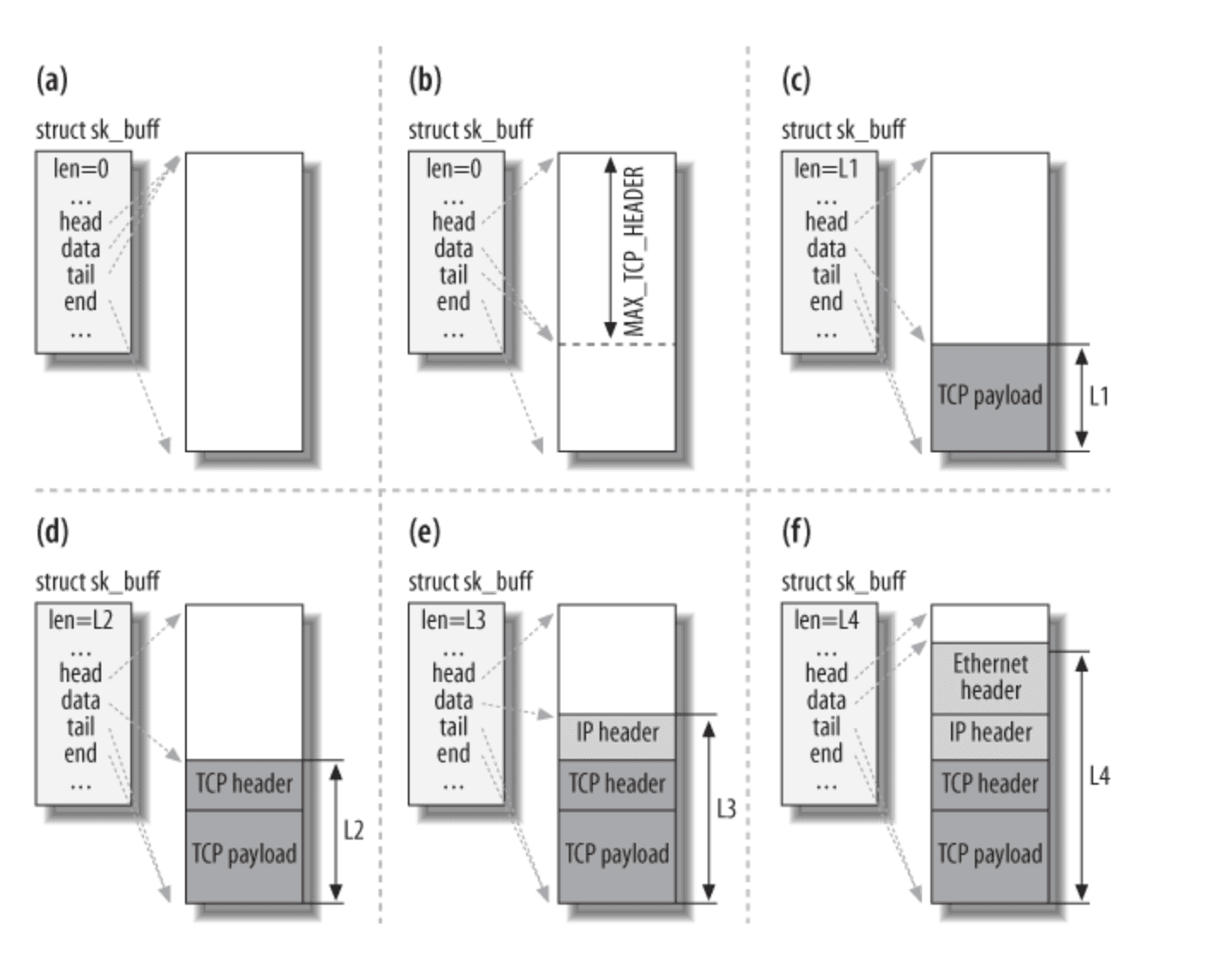
TCP パケットを送信する例を挙げると、この図では sk_buff が 6 つの段階を経ているのがわかります。
a. TCP のオプション(MSS など)に基づいてバッファを割り当てる。
b. MAX_TCP_HEADER に基づいて、申請したメモリバッファ内にすべてのネットワーク層のヘッダーを収容できるだけのスペースを確保する(TCP/IP/Link など)。
c. TCP のペイロードを埋め込む。
d. TCP ヘッダーを埋め込む。
e. IP ヘッダーを埋め込む。
f. リンクヘッダーを埋め込む。
TCP パケット構造を参照すると、より直感的に理解できるでしょう。
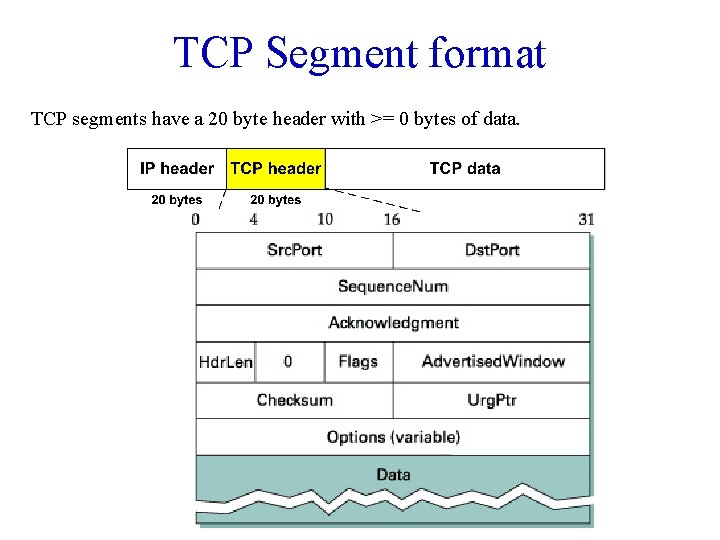
皆さんは、sk_buff のいくつかのポインタ操作を通じて、異なるレイヤーのヘッダーや具体的なペイロードを簡単に取得できることがわかります。
さて、私たちが必要な機能を実装する正式なステップに進みましょう。
eBPF + KProbe#
まず、eBPF について簡単に紹介します。BPF は Berkeley Packet Filter の略で、最初はカーネル内でネットワークパケットフィルタリング機能を実装するために設計されました。しかし、その後、コミュニティによって多くの強化が行われ、ネットワーク目的だけでなく、さまざまな用途に適用できるようになりました。これが名前の中の e の由来です(extend)。
本質的に、eBPF はカーネル内に VM のレイヤーを維持し、特定のルールに基づいて生成されたコードをロードできるようにし、カーネルをよりプログラム可能にします(後で、eBPF の入門から実践までの紹介記事を書こうと思います)。
ヒント: Tcpdump の背後には BPF があります。
この実装では、私たちは BCC を使用して、eBPF に関連するコーディングの難易度を簡素化しました。
では、コードを見てみましょう。
from bcc import BPF
import ctypes
bpf_text = """
#include <linux/ptrace.h>
#include <linux/sched.h> /* For TASK_COMM_LEN */
#include <linux/icmp.h>
#include <linux/ip.h>
#include <linux/netdevice.h>
struct probe_icmp_sample {
u32 pid;
u32 daddress;
u32 saddress;
};
BPF_PERF_OUTPUT(probe_events);
static inline unsigned char *custom_skb_network_header(const struct sk_buff *skb)
{
return skb->head + skb->network_header;
}
static inline struct iphdr *get_iphdr_in_icmp(const struct sk_buff *skb)
{
return (struct iphdr *)custom_skb_network_header(skb);
}
int probe_icmp(struct pt_regs *ctx, struct net *net, struct sock *sk, struct sk_buff *skb){
struct iphdr * ipdata=get_iphdr_in_icmp(skb);
if (ipdata->protocol!=1){
return 1;
}
u64 __pid_tgid = bpf_get_current_pid_tgid();
u32 __pid = __pid_tgid;
struct probe_icmp_sample __data = {0};
__data.pid = __pid;
u32 daddress;
u32 saddress;
bpf_probe_read(&daddress, sizeof(ipdata->daddr), &ipdata->daddr);
bpf_probe_read(&saddress, sizeof(ipdata->daddr), &ipdata->saddr);
__data.daddress=daddress;
__data.saddress=saddress;
probe_events.perf_submit(ctx, &__data, sizeof(__data));
return 0;
}
"""
class IcmpSamples(ctypes.Structure):
_fields_ = [
("pid", ctypes.c_uint32),
("daddress", ctypes.c_uint32),
("saddress", ctypes.c_uint32),
]
bpf = BPF(text=bpf_text)
filters = {}
def parse_ip_address(data):
results = [0, 0, 0, 0]
results[3] = data & 0xFF
results[2] = (data >> 8) & 0xFF
results[1] = (data >> 16) & 0xFF
results[0] = (data >> 24) & 0xFF
return ".".join([str(i) for i in results[::-1]])
def print_icmp_event(cpu, data, size):
# event = b["probe_icmp_events"].event(data)
event = ctypes.cast(data, ctypes.POINTER(IcmpSamples)).contents
daddress = parse_ip_address(event.daddress)
print(
f"pid:{event.pid}, daddress:{daddress}, saddress:{parse_ip_address(event.saddress)}"
)
bpf.attach_kprobe(event="ip_finish_output", fn_name="probe_icmp")
bpf["probe_events"].open_perf_buffer(print_icmp_event)
while 1:
try:
bpf.kprobe_poll()
except KeyboardInterrupt:
exit()
このコードは厳密には混合言語で、一部は C で、一部は Python です。Python 部分は皆さんがよく知っているもので、BCC が私たちの C コードをロードし、kprobe にアタッチします。そして、カーネルから外部に送信されるデータを継続的に出力します。
では、C 部分のコードを重点的に見てみましょう(実際には、これは厳密には標準 C ではなく、BCC によってラップされた DSL の一層です)。
まず、私たちの補助関数を見てみましょう。
static inline unsigned char *custom_skb_network_header(const struct sk_buff *skb)
{
return skb->head + skb->network_header;
}
static inline struct iphdr *get_iphdr_in_icmp(const struct sk_buff *skb)
{
return (struct iphdr *)custom_skb_network_header(skb);
}
前述のように、sk_buff の head と network_header に基づいて、IP ヘッダーがメモリ内に格納されているアドレスを計算し、それを iphdr 構造体ポインタにキャストします。
次に、iphdr を見てみましょう。
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*オプションはここから始まります。 */
};
IP パケット構造に精通している方は、saddr と daddr がそれぞれソースアドレスとターゲットアドレスであり、protocol が L4 プロトコルのタイプを示し、1 の場合は ICMP プロトコルを示すことがわかるでしょう。
次に、私たちのトレース関数を見てみましょう。
int probe_icmp(struct pt_regs *ctx, struct net *net, struct sock *sk, struct sk_buff *skb){
struct iphdr * ipdata=get_iphdr_in_icmp(skb);
if (ipdata->protocol!=1){
return 1;
}
u64 __pid_tgid = bpf_get_current_pid_tgid();
u32 __pid = __pid_tgid;
struct probe_icmp_sample __data = {0};
__data.pid = __pid;
u32 daddress;
u32 saddress;
bpf_probe_read(&daddress, sizeof(ipdata->daddr), &ipdata->daddr);
bpf_probe_read(&saddress, sizeof(ipdata->daddr), &ipdata->saddr);
__data.daddress=daddress;
__data.saddress=saddress;
probe_events.perf_submit(ctx, &__data, sizeof(__data));
return 0;
}
前述のように、kprobe がトリガーされると、ip_finish_output の 3 つのパラメータが私たちのトレース関数に渡されます。これにより、渡されたデータに基づいて多くのことを行うことができます。上記のコードで行われていることを紹介します。
- sk_buff を対応する iphdr に変換する。
- 現在のパケットが ICMP プロトコルであるかどうかを判断する。
- カーネル BPF が提供するヘルパー
bpf_get_current_pid_tgidを使用して、現在ip_finish_outputを呼び出しているプロセスの PID を取得する。 - saddr と daddr を取得する。ここで使用している bpf_probe_read も BPF が提供するヘルパー関数であり、原則として、eBPF では安全性を確保するために、カーネルからデータを読み取るすべての操作は
bpf_probe_readまたはbpf_probe_read_kernelを使用して実行する必要があります。 - perf を通じてデータを提出する。
これにより、私たちはマシン上で具体的にどのプロセスが ICMP リクエストを送信しているかを特定できるようになります。
効果を見てみましょう。

OK、私たちのニーズは基本的に達成されましたが、ここで小さな問題が残っています。皆さんは考えてみてください。PID に基づいて起動プロセスの cmdline を取得するにはどうすればよいでしょうか?
SystemTap + kprobe#
eBPF のバージョンは実装されましたが、1 つ問題があります。eBPF は高バージョンのカーネルでのみ使用できます。一般的に、x86_64 では、Linux 3.16 で eBPF がサポートされています。そして、私たちが依存している kprobe の eBPF サポートは Linux 4.1 で実装されました。通常、私たちは一般的に 4.9 以降のカーネルを eBPF と組み合わせて使用することを推奨します。
さて、問題が発生しました。実際、現在多くの CentOS 7 + Linux 3.10 のような従来の組み合わせがありますが、彼らはどうすればよいのでしょうか?
Linux 3.10 は重要です!CentOS 7 も重要です!
仕方がないので、別の技術スタックを使うことにしました。この時、私たちはまず RedHat が開発し、コミュニティに貢献した、低バージョンで使用可能な SystemTap を考慮します。
%{
#include<linux/byteorder/generic.h>
#include<linux/if_ether.h>
#include<linux/skbuff.h>
#include<linux/ip.h>
#include<linux/in.h>
#include<linux/tcp.h>
#include <linux/sched.h>
#include <linux/list.h>
#include <linux/pid.h>
#include <linux/mm.h>
%}
function isicmp:long (data:long)
%{
struct iphdr *ip;
struct sk_buff *skb;
int tmp = 0;
skb = (struct sk_buff *) STAP_ARG_data;
if (skb->protocol == htons(ETH_P_IP)){
ip = (struct iphdr *) skb->data;
tmp = (ip->protocol == 1);
}
STAP_RETVALUE = tmp;
%}
function task_execname_by_pid:string (pid:long) %{
struct task_struct *task;
task = pid_task(find_vpid(STAP_ARG_pid), PIDTYPE_PID);
// proc_pid_cmdline(p, STAP_RETVALUE);
snprintf(STAP_RETVALUE, MAXSTRINGLEN, "%s", task->comm);
%}
function ipsource:long (data:long)
%{
struct sk_buff *skb;
struct iphdr *ip;
__be32 src;
skb = (struct sk_buff *) STAP_ARG_data;
ip = (struct iphdr *) skb->data;
src = (__be32) ip->saddr;
STAP_RETVALUE = src;
%}
/* IP の宛先アドレスを返す */
function ipdst:long (data:long)
%{
struct sk_buff *skb;
struct iphdr *ip;
__be32 dst;
skb = (struct sk_buff *) STAP_ARG_data;
ip = (struct iphdr *) skb->data;
dst = (__be32) ip->daddr;
STAP_RETVALUE = dst;
%}
function parseIp:string (data:long) %{
sprintf(STAP_RETVALUE,"%d.%d,%d.%d",(int)STAP_ARG_data &0xFF,(int)(STAP_ARG_data>>8)&0xFF,(int)(STAP_ARG_data>>16)&0xFF,(int)(STAP_ARG_data>>24)&0xFF);
%}
probe kernel.function("ip_finish_output").call {
if (isicmp($skb)) {
pid_data = pid()
/* IP */
ipdst = ipdst($skb)
ipsrc = ipsource($skb)
printf("pid is:%d,source address is:%s, destination address is %s, command is: '%s'\n",pid_data,parseIp(ipsrc),parseIp(ipdst),task_execname_by_pid(pid_data))
} else {
next
}
}
実際、皆さんは、私たちの考え方は同じであることがわかるでしょう。kprobe のフックポイントとして ip_finish_output を利用し、対応する iphdr を取得して操作を行います。
さて、私たちのニーズの基本機能はほぼこれで完成しました。皆さんは、プロセスの cmdline を取得するなど、追加の機能強化を行うことができます。
さらなるアイデアと実験#
皆さんは ICMP のようなマイナーなプロトコルに対してあまり明確な感覚を持っていないかもしれませんが、別のニーズに変えると、皆さんはもっと感じるかもしれません。
マシン上でどのプロセスが HTTP 1.1 リクエストを発信しているかを監視する。
さて、いつものように、まずはシステム内の重要な呼び出しを見てみましょう。
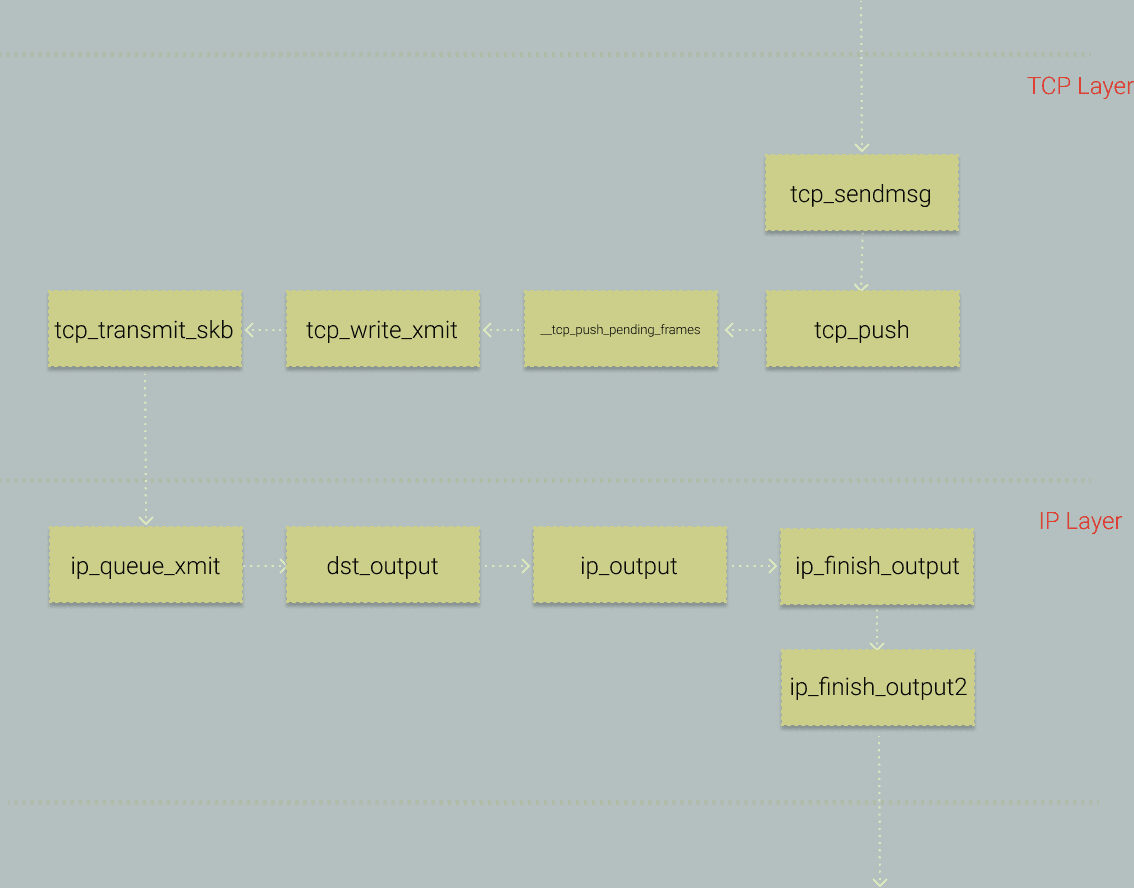
ここで、tcp_sendmsg を切り口として選択します。
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
ここで、sock はいくつかの重要なメタデータを含む構造体です。
struct sock {
/*
* 現在、struct inet_timewait_sock も sock_common を使用しているため、この最初のメンバー (__sk_common) の前に何も追加しないでください --acme
*/
struct sock_common __sk_common;
...
}
struct sock_common {
/* skc_daddr と skc_rcv_saddr は、64 ビットアーキテクチャの 8 バイト境界に整列されたアドレスにグループ化する必要があります : cf INET_MATCH()
*/
union {
__addrpair skc_addrpair;
struct {
__be32 skc_daddr;
__be32 skc_rcv_saddr;
};
};
union {
unsigned int skc_hash;
__u16 skc_u16hashes[2];
};
/* skc_dport と skc_num もグループ化する必要があります */
union {
__portpair skc_portpair;
struct {
__be16 skc_dport;
__u16 skc_num;
};
};
...
}
皆さんは、sock の中でポートの 5 元組データを取得できることがわかります。そして、msghdr から具体的なデータを取得できます。
さて、私たちのニーズにおける HTTP の例では、実際には、取得した TCP パケットに HTTP/1.1 が含まれているかどうかを判断するだけで、リクエストが HTTP 1.1 リクエストであるかどうかを粗略に判断できます(非常に乱暴な方法です Hhhhh)。
では、コードを見てみましょう。
from bcc import BPF
import ctypes
import binascii
bpf_text = """
#include <linux/ptrace.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <uapi/linux/ptrace.h>
#include <net/sock.h>
#include <bcc/proto.h>
#include <linux/socket.h>
struct ipv4_data_t {
u32 pid;
u64 ip;
u32 saddr;
u32 daddr;
u16 lport;
u16 dport;
u64 state;
u64 type;
u8 data[300];
u16 data_size;
};
BPF_PERF_OUTPUT(ipv4_events);
int trace_event(struct pt_regs *ctx,struct sock *sk, struct msghdr *msg, size_t size){
if (sk == NULL)
return 0;
u32 pid = bpf_get_current_pid_tgid() >> 32;
// 詳細を引き込む
u16 family = sk->__sk_common.skc_family;
u16 lport = sk->__sk_common.skc_num;
u16 dport = sk->__sk_common.skc_dport;
char state = sk->__sk_common.skc_state;
if (family == AF_INET) {
struct ipv4_data_t data4 = {};
data4.pid = pid;
data4.ip = 4;
//data4.type = type;
data4.saddr = sk->__sk_common.skc_rcv_saddr;
data4.daddr = sk->__sk_common.skc_daddr;
// lport はホストオーダー
data4.lport = lport;
data4.dport = ntohs(dport);
data4.state = state;
struct iov_iter temp_iov_iter=msg->msg_iter;
struct iovec *temp_iov=temp_iov_iter.iov;
bpf_probe_read_kernel(&data4.data_size, 4, &temp_iov->iov_len);
u8 * temp_ptr;
bpf_probe_read_kernel(&temp_ptr, sizeof(temp_ptr), &temp_iov->iov_base);
bpf_probe_read_kernel(&data4.data, sizeof(data4.data), temp_ptr);
ipv4_events.perf_submit(ctx, &data4, sizeof(data4));
}
return 0;
}
"""
bpf = BPF(text=bpf_text)
filters = {}
def parse_ip_address(data):
results = [0, 0, 0, 0]
results[3] = data & 0xFF
results[2] = (data >> 8) & 0xFF
results[1] = (data >> 16) & 0xFF
results[0] = (data >> 24) & 0xFF
return ".".join([str(i) for i in results[::-1]])
def print_http_payload(cpu, data, size):
# event = b["probe_icmp_events"].event(data)
# event = ctypes.cast(data, ctypes.POINTER(IcmpSamples)).contents
event= bpf["ipv4_events"].event(data)
daddress = parse_ip_address(event.daddr)
# data=list(event.data)
# temp=binascii.hexlify(data)
body = bytearray(event.data).hex()
if "48 54 54 50 2f 31 2e 31".replace(" ", "") in body:
# if "68747470" in temp.decode():
print(
f"pid:{event.pid}, daddress:{daddress}, saddress:{parse_ip_address(event.saddr)}, {event.lport}, {event.dport}, {event.data_size}"
)
bpf.attach_kprobe(event="tcp_sendmsg", fn_name="trace_event");
bpf["ipv4_events"].open_perf_buffer(print_http_payload)
while 1:
try:
bpf.perf_buffer_poll()
except KeyboardInterrupt:
exit()
OK、効果を見てみましょう。
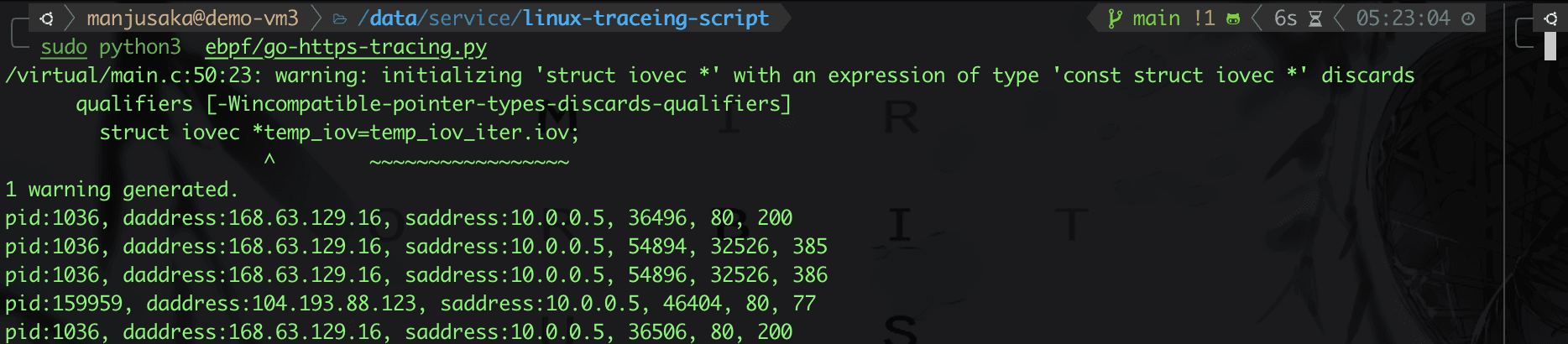
実際、これをさらに拡張することもできます。たとえば、Go のように、特定の HTTPS 接続を発信する言語には固定の特徴があるため、比較的簡単な方法でマシン上のパケットの出所を追跡することができます(皆さんは無辄のこの記事を参考にしてください、なぜ Go で特定のウェブサイトにアクセスすると常に 503 Service Unavailable になるのか?)。
私自身もテストを行い、皆さんはコードを参考にしてください:https://github.com/Zheaoli/linux-traceing-script/blob/main/ebpf/go-https-tracing.py
まとめ#
実際、eBPF でも SystemTap でも、このような動的 tracing 技術は Linux カーネルをよりプログラム可能にします。従来のカーネルを再コンパイルする手段と比較して、より便利で迅速です。また、BCC/BPFTrace のようなさらに進んだラッピングフレームワークの登場により、カーネルを観測する難易度がさらに低下しました。
多くの場合、私たちのニーズはバイパス方式でより迅速に実現できます。しかし、注意すべき点は、動的 tracing 技術の導入はカーネルの不安定性を増加させ、ある程度パフォーマンスに影響を与えることです。したがって、具体的なシナリオに基づいてトレードオフを行う必要があります。
さて、この記事はここまでです。後で時間があれば、eBPF の入門から実践までのシリーズ記事を出すことを目指します(フラグ ++)。