I wasn't feeling well today and took a day off at home. Suddenly, I remembered some recent issues and looked into UID in containers. So, let's have a brief discussion about this topic. Consider it a beginner's article.
Introduction#
Recently, I helped FrostMing deploy his tokei-pie-cooker to my K8S as a SaaS service. Frost initially provided me with an image address. Then I quickly copied and pasted a Deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tokei-pie
namespace: tokei-pie
labels:
app: tokei-pie
spec:
replicas: 12
selector:
matchLabels:
app: tokei-pie
template:
metadata:
labels:
app: tokei-pie
spec:
containers:
- name: tokei-pie
image: frostming/tokei-pie-cooker:latest
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: "2Gi"
ephemeral-storage: "3Gi"
requests:
cpu: "500m"
memory: "500Mi"
ephemeral-storage: "1Gi"
securityContext:
allowPrivilegeEscalation: false
runAsNonRoot: true
That was quick and simple, right? I limited the storage usage and set NonRoot to avoid being compromised. Fine, I executed kubectl apply -f. Ops,
Error: container has runAsNonRoot and image has non-numeric user (tokei), cannot verify user is non-root (pod: "tokei-pie-6c6fd5cb84-s4bz7_tokei-pie(239057ea-fe47-40a9-8041-966c65344a44)", container: tokei-pie)
Oh, intercepted by K8$, the interception point is in pkg/kubelet/kuberruntime/security_context_others.go.
func verifyRunAsNonRoot(pod *v1.Pod, container *v1.Container, uid *int64, username string) error {
effectiveSc := securitycontext.DetermineEffectiveSecurityContext(pod, container)
// If the option is not set, or if running as root is allowed, return nil.
if effectiveSc == nil || effectiveSc.RunAsNonRoot == nil || !*effectiveSc.RunAsNonRoot {
return nil
}
if effectiveSc.RunAsUser != nil {
if *effectiveSc.RunAsUser == 0 {
return fmt.Errorf("container's runAsUser breaks non-root policy (pod: %q, container: %s)", format.Pod(pod), container.Name)
}
return nil
}
switch {
case uid != nil && *uid == 0:
return fmt.Errorf("container has runAsNonRoot and image will run as root (pod: %q, container: %s)", format.Pod(pod), container.Name)
case uid == nil && len(username) > 0:
return fmt.Errorf("container has runAsNonRoot and image has non-numeric user (%s), cannot verify user is non-root (pod: %q, container: %s)", username, format.Pod(pod), container.Name)
default:
return nil
}
}
In short, K8$ first retrieves the Running Username from the image's manifest. If you have set a Running Username in your image and you set runAsNonRoot, but you haven't set the run uid, it will throw an error. Makes sense, if the uid of the specified username is 0, then it effectively bypasses the SecurityContext restrictions.
I asked Frost for his Dockerfile, as follows:
FROM python:3.10-slim
RUN useradd -m tokei
USER tokei
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY templates /app/templates
COPY app.py .
COPY gunicorn_config.py .
ENV PATH="/home/tokei/.local/bin:$PATH"
EXPOSE 8000
CMD ["gunicorn", "-c", "gunicorn_config.py"]
OK, plain and simple, no exceptions. OK, then I quickly modified the Deployment, the new version is as follows:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tokei-pie
namespace: tokei-pie
labels:
app: tokei-pie
spec:
replicas: 12
selector:
matchLabels:
app: tokei-pie
template:
metadata:
labels:
app: tokei-pie
spec:
containers:
- name: tokei-pie
image: frostming/tokei-pie-cooker:latest
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: "2Gi"
ephemeral-storage: "3Gi"
requests:
cpu: "500m"
memory: "500Mi"
ephemeral-storage: "1Gi"
securityContext:
allowPrivilegeEscalation: false
runAsNonRoot: true
runAsUser: 10086
I chose my own Magic Number, 10086, so there shouldn't be any issues now. I executed kubectl apply -f again. Oooops, a brand new error.
/usr/local/bin/python: can't open file '/home/tokei/.local/bin/gunicorn': [Errno 13] Permission denied
OK, I abandoned my Magic Number and switched to the legendary number, 1000, to see what happens. OK, Works!
So what is the reason behind all this? Next, I will tell you (XD).
A Simple Introduction, Complete Joy#
UID in Containers#
First, let's discuss some background knowledge. The UID allocation rules in Linux. In a Linux UserNamespace, the default range of UIDs is from 0 to 60000. UID 0 is reserved for Root. Theoretically, the range for creating user UIDs/GIDs is from 1 to 60000.
However, it can be more complex; typically, some built-in services in various distributions may come with special users, such as the classic www-data (which those who used to set up blogs are definitely familiar with). Therefore, in practice, the starting UID in a User Namespace is usually 500 or 1000. The specific settings depend on a special file, login.defs, located at /etc/login.defs.
The official documentation describes it as follows:
Range of user IDs used for the creation of regular users by useradd or newusers. The default value for UID_MIN (resp. UID_MAX) is 1000 (resp. 60000).
When we call useradd to add a user while building a Dockerfile, the corresponding user information will be added to the special file /etc/passwd after the relevant operations are completed. For Frost's Dockerfile, the final contents of the passwd file are as follows:
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
_apt:x:100:65534::/nonexistent:/usr/sbin/nologin
tokei:x:1000:1000::/home/tokei:/bin/sh
After the build is complete, let's look at how one of the common container runtimes, Docker, handles this.
Here, we need to explain a bit of background knowledge. Docker is essentially a Daemon+CLI; its core function is to call the containerd behind it. containerd ultimately creates the relevant containers through runc.
Now, let's look at how runc handles this.
When runc creates a container, it calls the function runc/libcontainer/init_linux.go.finalizeNamespace to complete some settings. In this function, it calls runc/libcontainer/init_linux.go.setupUser to set up the Exec User. Let's take a look at the source code.
func setupUser(config *initConfig) error {
// Set up defaults.
defaultExecUser := user.ExecUser{
Uid: 0,
Gid: 0,
Home: "/",
}
passwdPath, err := user.GetPasswdPath()
if err != nil {
return err
}
groupPath, err := user.GetGroupPath()
if err != nil {
return err
}
execUser, err := user.GetExecUserPath(config.User, &defaultExecUser, passwdPath, groupPath)
if err != nil {
return err
}
var addGroups []int
if len(config.AdditionalGroups) > 0 {
addGroups, err = user.GetAdditionalGroupsPath(config.AdditionalGroups, groupPath)
if err != nil {
return err
}
}
// Rather than just erroring out later in setuid(2) and setgid(2), check
// that the user is mapped here.
if _, err := config.Config.HostUID(execUser.Uid); err != nil {
return errors.New("cannot set uid to unmapped user in user namespace")
}
if _, err := config.Config.HostGID(execUser.Gid); err != nil {
return errors.New("cannot set gid to unmapped user in user namespace")
}
if config.RootlessEUID {
// We cannot set any additional groups in a rootless container and thus
// we bail if the user asked us to do so. TODO: We currently can't do
// this check earlier, but if libcontainer.Process.User was typesafe
// this might work.
if len(addGroups) > 0 {
return errors.New("cannot set any additional groups in a rootless container")
}
}
// Before we change to the container's user make sure that the processes
// STDIO is correctly owned by the user that we are switching to.
if err := fixStdioPermissions(config, execUser); err != nil {
return err
}
setgroups, err := ioutil.ReadFile("/proc/self/setgroups")
if err != nil && !os.IsNotExist(err) {
return err
}
// This isn't allowed in an unprivileged user namespace since Linux 3.19.
// There's nothing we can do about /etc/group entries, so we silently
// ignore setting groups here (since the user didn't explicitly ask us to
// set the group).
allowSupGroups := !config.RootlessEUID && string(bytes.TrimSpace(setgroups)) != "deny"
if allowSupGroups {
suppGroups := append(execUser.Sgids, addGroups...)
if err := unix.Setgroups(suppGroups); err != nil {
return err
}
}
if err := system.Setgid(execUser.Gid); err != nil {
return err
}
if err := system.Setuid(execUser.Uid); err != nil {
return err
}
// if we didn't get HOME already, set it based on the user's HOME
if envHome := os.Getenv("HOME"); envHome == "" {
if err := os.Setenv("HOME", execUser.Home); err != nil {
return err
}
}
return nil
}
From the comments, you should be able to understand what this code is doing. This code will call runc/libcontainer/user/user.go.GetExecUserPath and runc/libcontainer/user/user.go.GetExecUser to get the UID when executing. Let's take a look at this implementation (the following code is a simplified version).
func GetExecUser(userSpec string, defaults *ExecUser, passwd, group io.Reader) (*ExecUser, error) {
if defaults == nil {
defaults = new(ExecUser)
}
// Copy over defaults.
user := &ExecUser{
Uid: defaults.Uid,
Gid: defaults.Gid,
Sgids: defaults.Sgids,
Home: defaults.Home,
}
// Sgids slice *cannot* be nil.
if user.Sgids == nil {
user.Sgids = []int{}
}
// Allow for userArg to have either "user" syntax, or optionally "user:group" syntax
var userArg, groupArg string
parseLine([]byte(userSpec), &userArg, &groupArg)
// Convert userArg and groupArg to be numeric, so we don't have to execute
// Atoi *twice* for each iteration over lines.
uidArg, uidErr := strconv.Atoi(userArg)
gidArg, gidErr := strconv.Atoi(groupArg)
// Find the matching user.
users, err := ParsePasswdFilter(passwd, func(u User) bool {
if userArg == "" {
// Default to current state of the user.
return u.Uid == user.Uid
}
if uidErr == nil {
// If the userArg is numeric, always treat it as a UID.
return uidArg == u.Uid
}
return u.Name == userArg
})
if err != nil && passwd != nil {
if userArg == "" {
userArg = strconv.Itoa(user.Uid)
}
return nil, fmt.Errorf("unable to find user %s: %v", userArg, err)
}
var matchedUserName string
if len(users) > 0 {
// First match wins, even if there's more than one matching entry.
matchedUserName = users[0].Name
user.Uid = users[0].Uid
user.Gid = users[0].Gid
user.Home = users[0].Home
} else if userArg != "" {
// If we can't find a user with the given username, the only other valid
// option is if it's a numeric username with no associated entry in passwd.
if uidErr != nil {
// Not numeric.
return nil, fmt.Errorf("unable to find user %s: %v", userArg, ErrNoPasswdEntries)
}
user.Uid = uidArg
// Must be inside valid uid range.
if user.Uid < minID || user.Uid > maxID {
return nil, ErrRange
}
// Okay, so it's numeric. We can just roll with this.
}
}
This looks complex, but in summary, it does the following:
-
First, it reads all known users from
/etc/passwd. -
If the user provided a username at startup, it checks if there is a matching username. If not, the startup fails.
-
If the user provided a UID at startup, it checks if there is a corresponding user among the known users. If there is, it sets that user. If not, it sets the process's UID to the provided UID.
-
If the user didn't provide anything, it defaults to the first user in
/etc/passwd, which is usually the root user with UID 0.
Now, back to our Deployment, we can draw the following conclusions:
-
If we don't set runAsUser and the image doesn't specify a startup user, the process in our container will start as the root user with UID 0 in the current user namespace.
-
If a user is specified in the Dockerfile and runAsUser is not set, it will start with the user specified in the Dockerfile.
-
If we set runAsUser and the Dockerfile also specifies a user, the process will start with the UID specified by runAsUser.
OK, at this point, it seems the issue is resolved. However, a new question arises. Generally, when creating files, the default permissions are 755, meaning that non-current users and non-members of the current user group have read and execute permissions. Therefore, the [Errno 13] Permission denied situation shouldn't occur.
I checked the file that caused the error in the container, and indeed, it had 755 permissions as I expected.
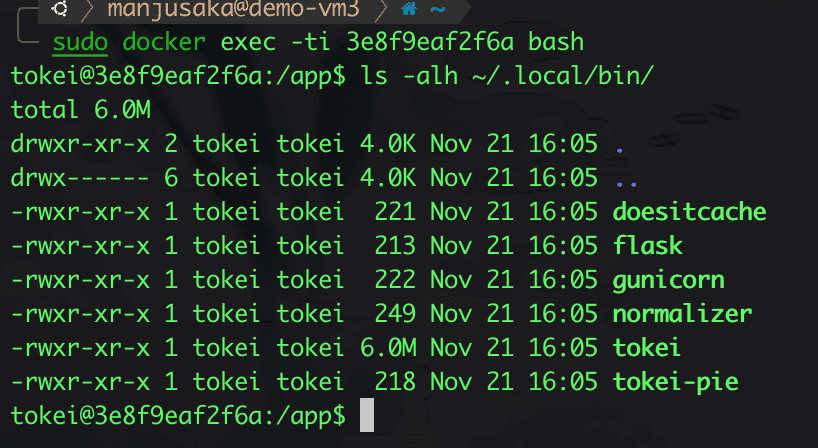
So where's the problem? The issue lies in the ~/.local/ directory.
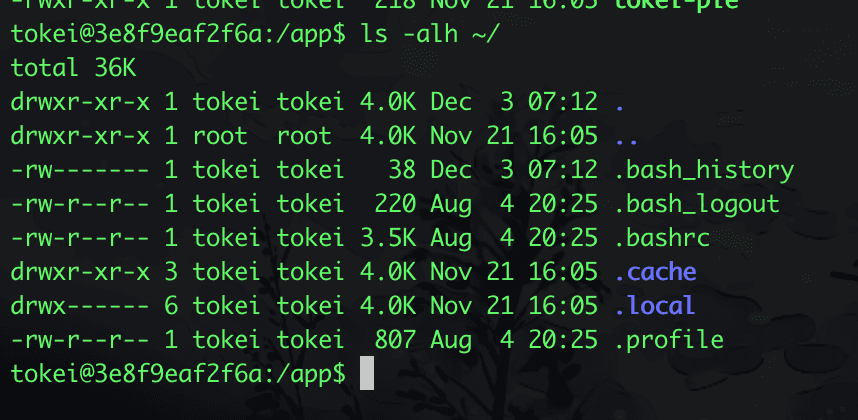
Yes, that's right, the .local directory has 700 permissions, meaning that non-current users and non-members of the current user group have no executable permissions for the current directory. You might be a bit confused about what directory executable permissions mean. Here’s a description from the official documentation Understanding Linux File Permissions:
execute – The Execute permission affects a user’s capability to execute a file or view the contents of a directory.
OK, if there are no executable permissions for the corresponding directory, we cannot execute the files within that directory, even if we have executable permissions for the files.
I looked through the pip source code and found that when pip installs in user mode, if the .local directory does not exist, it creates it and sets the permissions to 700.
At this point, the entire causal chain of our problem has been established:
In the Dockerfile, we create and set the user tokei with uid 1000 -> pip created a
.localdirectory with permissions set to 700 ->.localbelongs to the user with UID 1000 -> We set runAsUser to a non-1000 number -> No executable permissions for.local-> Error.
To be honest, I can understand why pip is designed this way, but I think this design breaks some conventional rules, and its rationality is debatable.
Conclusion#
This issue wasn't too difficult to trace, but the location where it occurred was somewhat unexpected. From my perspective, it ultimately stems from pip not adhering to basic conventions, resulting in a bit of a mess.
Here's a question for everyone to ponder: We all know that Docker has a command docker cp which copies files from the host to a running container or vice versa. There’s a parameter -a, which preserves the original file's UID/GID. If we use this parameter to copy files from the host/container to the container/host, what kind of User/UserGroup information can we see when we run ls -lh?
Alright, I'll stop here for this water article. Writing water articles is really enjoyable. If I have time over the weekend, I might write another article discussing an interesting method I encountered recently for analyzing SSL traffic based on feature blocking.
Okay, I'm off!