新年が明けましたので、時間があるうちに技術的な水文をいくつか書くことにしました。今日は、私たちが毎日接触するけれども、しばしば見落とされがちなコンテナ内の 1 号プロセスについて簡単に話したいと思います。
本文#
コンテナ技術は現在に至るまで、実際に形態が大きく変化しています。異なるシーンに応じて、従来の Docker1 や containerd2 のような、CGroup + Namespace に基づく従来型のコンテナ形態もあれば、Kata3 のような、VM に基づく新型のコンテナ形態も存在します。本記事では主に従来のコンテナにおける 1 号プロセスに焦点を当てます。
私たちは、従来のコンテナが依存している CGroup + Namespace によってリソースを隔離していることを知っていますが、本質的には OS 内の一つのプロセスです。したがって、コンテナに関連する内容をさらに掘り下げる前に、まずは Linux におけるプロセス管理について簡単に話しましょう。
Linux におけるプロセス管理#
プロセスについて簡単に#
Linux におけるプロセスは、実際には非常に大きなトピックです。もし詳細に話すと、このトピックは一冊の本に相当しますので、時間を考慮して、最も核心的な部分に焦点を当てましょう(実際には、私も多くのことを理解していませんが)。
まず、カーネル内で特別な構造体を利用してプロセスに関する情報を管理しています。例えば、一般的な PID、プロセスの状態、オープンしているファイルディスクリプタなどの情報です。カーネルコード内では、この構造体は task_struct4 と呼ばれ、その大まかな構造は以下の図で確認できます。
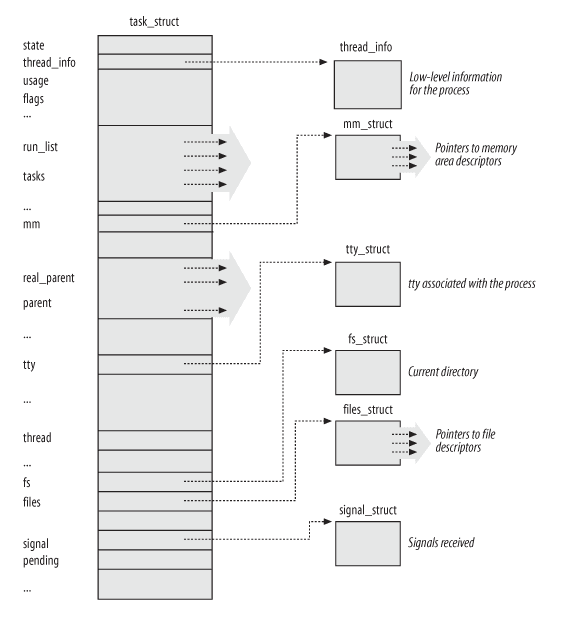
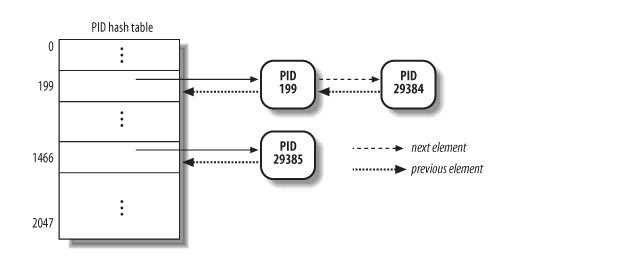
通常、システム上で多くのプロセスを実行します。そのため、カーネルはプロセステーブル(実際には Linux ではプロセステーブルを管理するために複数のデータ構造が存在しますが、ここでは PID ハッシュマップを例に挙げます)を用いて、すべてのプロセスディスクリプタに関連する情報を管理しています。詳細は以下の図を参照してください。
さて、ここでプロセスの基本構造について大まかに理解できましたので、次に一般的なプロセスの使用シーンである親子プロセスについて見ていきましょう。私たちは時々、fork5 というシステムコールを使って、新しいプロセスを作成します。通常、新しく作成したプロセスは現在のプロセスの子プロセスです。では、カーネル内ではこの親子関係をどのように表現しているのでしょうか?
先ほど言及した task_struct に戻ると、この構造体には親子関係を表すためのいくつかのフィールドがあります。
- real_parent:親プロセスを指す task_struct ポインタ
- parent: 親プロセスを指す task_struct ポインタ。ほとんどの場合、このフィールドの値は
real_parentと一致しますが、現在のプロセスが ptrace6 を使用する場合など、real_parentフィールドとは一致しないことがあります。 - children:list_head、現在のプロセスが作成したすべての子プロセスの双方向リストを指します。
ここで少し抽象的な話をしましたが、図を見ればわかりやすくなります。
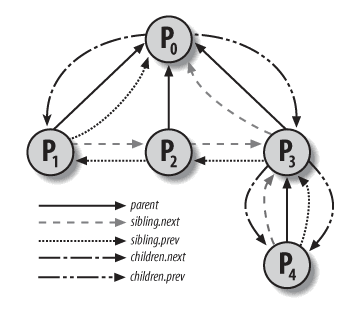
実際には、異なるプロセス間の親子関係は、具体的なデータ構造に反映されると、完全なツリー構造を形成します(この点を覚えておいてください。後で再度触れます)。
ここまでで、Linux におけるプロセスについての基本的な概念を理解しました。次に、プロセス使用中によく遭遇する 2 つの問題、孤児プロセスとゾンビプロセスについて話しましょう。
孤児プロセス && ゾンビプロセス#
まず、ゾンビプロセス という概念について話しましょう。
前述のように、カーネルにはプロセステーブルがあり、プロセスディスクリプタに関連する情報を管理しています。Linux の設計では、子プロセスが終了すると、そのプロセスに関連する状態が保存され、親プロセスがそれを使用できるようになります。親プロセスは waitpid7 を呼び出して子プロセスの状態を取得し、関連リソースをクリーンアップします。
したがって、親プロセスは子プロセスの状態を取得する必要がある場合があるため、カーネル内のプロセステーブルは関連リソースを保持し続けます。ゾンビプロセスが増えると、大きなリソースの浪費を引き起こすことになります。
まずは、シンプルなゾンビプロセスの例を見てみましょう。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
if ((pid = fork()) == 0) {
printf("子プロセスです\n");
} else {
printf("子プロセスの PID は %d です\n", pid);
sleep(20);
}
return 0;
}
このコードをコンパイルして実行し、ps コマンドで確認すると、確かにゾンビプロセスが生成されていることがわかります。
![]()
次に、子プロセスの終了を正しく処理するコードを見てみましょう。
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/signalfd.h>
#include <sys/wait.h>
#define MAXEVENTS 64
void deletejob(pid_t pid) { printf("タスク %d を削除します\n", pid); }
void addjob(pid_t pid) { printf("タスク %d を追加します\n", pid); }
int main(int argc, char **argv) {
int pid;
struct epoll_event event;
struct epoll_event *events;
sigset_t mask;
sigemptyset(&mask);
sigaddset(&mask, SIGCHLD);
if (sigprocmask(SIG_SETMASK, &mask, NULL) < 0) {
perror("sigprocmask");
return 1;
}
int sfd = signalfd(-1, &mask, 0);
int epoll_fd = epoll_create(MAXEVENTS);
event.events = EPOLLIN | EPOLLEXCLUSIVE | EPOLLET;
event.data.fd = sfd;
int s = epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1) {
abort();
}
events = calloc(MAXEVENTS, sizeof(event));
while (1) {
int n = epoll_wait(epoll_fd, events, MAXEVENTS, 1);
if (n == -1) {
if (errno == EINTR) {
fprintf(stderr, "epoll EINTR エラー\n");
} else if (errno == EINVAL) {
fprintf(stderr, "epoll EINVAL エラー\n");
} else if (errno == EFAULT) {
fprintf(stderr, "epoll EFAULT エラー\n");
exit(-1);
} else if (errno == EBADF) {
fprintf(stderr, "epoll EBADF エラー\n");
exit(-1);
}
}
printf("%d\n", n);
for (int i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
printf("%d\n", i);
fprintf(stderr, "epoll エラー\n");
close(events[i].data.fd);
continue;
} else if (sfd == events[i].data.fd) {
struct signalfd_siginfo si;
ssize_t res = read(sfd, &si, sizeof(si));
if (res < 0) {
fprintf(stderr, "読み取りエラー\n");
continue;
}
if (res != sizeof(si)) {
fprintf(stderr, "何かが間違っています\n");
continue;
}
if (si.ssi_signo == SIGCHLD) {
printf("SIGCHLD を受信しました\n");
int child_pid = waitpid(-1, NULL, 0);
deletejob(child_pid);
}
}
}
if ((pid = fork()) == 0) {
execve("/bin/date", argv, NULL);
}
addjob(pid);
}
}
ここで、子プロセスが終了した後、親プロセスが関連リソースを正しく回収する必要があることがわかりました。さて、問題が発生します。親プロセスが子プロセスより先に終了した場合はどうなるのでしょうか。実際、これは非常に一般的なシーンです。例えば、2 回の fork を使用してデーモンプログラムを実装する場合などです。
一般的な認識として、親プロセスが終了すると、そのプロセスに属するすべての子プロセスは、現在の PID 名前空間の 1 号プロセスに再親化されると考えられます。この答えは正しいのでしょうか?はい、しかしそうでない場合もあります。まずは例を見てみましょう。
#include <stdio.h>
#include <sys/prctl.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
int err = prctl(PR_SET_CHILD_SUBREAPER, 1);
if (err != 0) {
return 0;
}
if ((pid = fork()) == 0) {
if ((pid = fork()) == 0) {
printf("子プロセス1です\n");
sleep(20);
} else {
printf("子プロセスの PID は %d です\n", pid);
}
} else {
sleep(40);
}
return 0;
}
これは、デーモンプログラムを作成するための典型的な 2 回の fork を使用したコードです(SIGCHLD の処理は書いていませんが)。このコードの出力を見てみましょう。
守護プロセスの PID は 449920 です。
次に、ps -efj と ps auf の 2 つのコマンドを実行して結果を確認します。

449920 というプロセスは、親プロセスが終了した後に現在の名前空間の 1 号プロセスに再親化されていないことがわかります。これはなぜでしょうか?鋭い方は、このコードに特別なシステムコール prctl8 が含まれていることに気づいているかもしれません。現在のプロセスに PR_SET_CHILD_SUBREAPER の属性を設定しました。
ここで、カーネル内の実装を見てみましょう。
/*
* 私たちが死ぬとき、すべての子プロセスを再親化し、次のことを試みます:
* 1. もしスレッドグループ内に他のスレッドが存在する場合、そのスレッドに渡す
* 2. 子プロセスのために自分自身を子サブリーパーとして設定した最初の祖先プロセスに渡す(サービスマネージャーのように)
* 3. 現在の PID 名前空間の init プロセス(PID 1)に渡す
*/
static struct task_struct *find_new_reaper(struct task_struct *father,
struct task_struct *child_reaper)
{
struct task_struct *thread, *reaper;
thread = find_alive_thread(father);
if (thread)
return thread;
if (father->signal->has_child_subreaper) {
unsigned int ns_level = task_pid(father)->level;
/*
* 現在の pid_ns 内で最初の ->is_child_subreaper 祖先を探します。
* reaper != child_reaper をチェックできないのは、名前空間を越えないようにするためです。
* exiting parent が setns() + fork() によって注入される可能性があります。
* pid->level をチェックします。これは、task_active_pid_ns(reaper) != task_active_pid_ns(father) よりもわずかに効率的です。
*/
for (reaper = father->real_parent;
task_pid(reaper)->level == ns_level;
reaper = reaper->real_parent) {
if (reaper == &init_task)
break;
if (!reaper->signal->is_child_subreaper)
continue;
thread = find_alive_thread(reaper);
if (thread)
return thread;
}
}
return child_reaper;
}
ここでまとめると、親プロセスが終了した後、所属する子プロセスは次の順序で再親化されます。
- スレッドグループ内の他の利用可能なスレッド(ここでのスレッドは少し異なる場合がありますので、一時的に無視しても構いません)
- 現在のプロセスツリー内で PR_SET_CHILD_SUBREAPER を設定したプロセスを探し続ける
- 前の 2 つが無効な場合、現在の PID 名前空間の 1 号プロセスに再親化される
ここまでで、Linux におけるプロセス管理の基礎的な紹介が完了しました。それでは、コンテナ内の状況について話しましょう。
コンテナ内の 1 号プロセス#
ここでは、Docker を背景にこのトピックについて話します。まず、Docker 1.11 以降、そのアーキテクチャは大きく変化しました。以下の図を見てください。
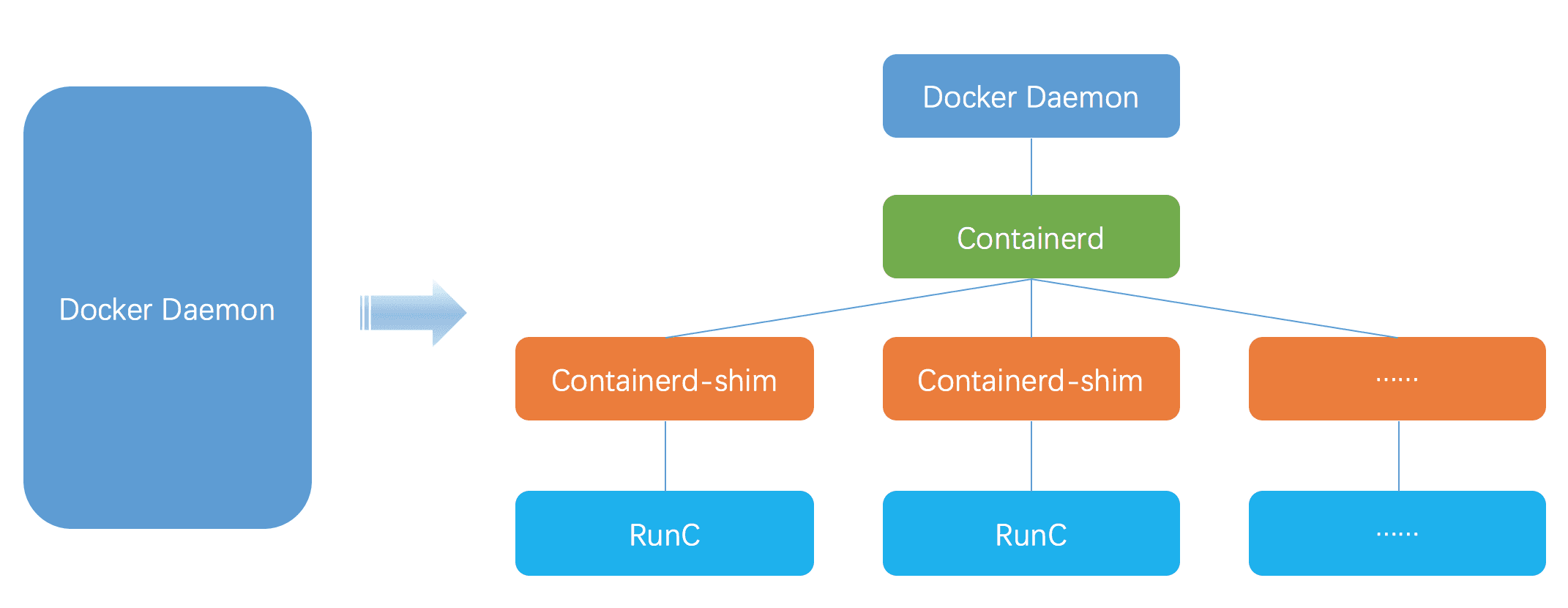
コンテナを起動するプロセスは以下の通りです。
- Docker Daemon が containerd に指示を送信します。
- containerd が containterd-shim プロセスを作成します。
- containerd-shim が runc プロセスを作成します。
- runc プロセスは OCI 標準に基づいて、関連する環境を設定し(cgroup を作成し、ns を作成するなど)、
entrypointで指定されたコマンドを実行します。 - runc は関連設定を実行した後、自身を終了します。この時、その子プロセス(つまり、コンテナ名前空間内の 1 号プロセス)は containerd-shim プロセスに再親化されます。
さて、上記のステップ 5 の操作は、前のセクションで説明した prctl と PR_SET_CHILD_SUBREAPER に依存しています。
これにより、containerd-shim はコンテナ内のプロセスに関連する操作を引き受けます。親プロセスが終了しても、子プロセスは再親化のプロセスに従って containerd-shim プロセスに管理されます。
では、これで問題はないのでしょうか?
答えは明らかに「いいえ」です。実際のシーンを挙げてみましょう。例えば、あるサービスが「優雅なシャットダウン」という要件を実現する必要があるとします。通常、プロセスを強制終了する前に、SIGTERM 信号を利用してこの機能を実現します。しかし、コンテナの時代には問題があります。1 号プロセスがプログラムそのものでない場合(例えば、entrypoint で bash を使ってラップすることが一般的です)、または特別なシーンでコンテナ内のプロセスがすべて containerd-shim に管理されている場合、containerd-shim は信号転送の能力を持っていません。
したがって、このようなシーンでは、私たちの要件を満たすために追加のコンポーネントを導入する必要があります。ここでは、コンテナ専用に設計された非常に軽量な 1 号プロセクトプロジェクト tini9 を紹介します。
ここで、いくつかのコアコードを見てみましょう。
int register_subreaper () {
if (subreaper > 0) {
if (prctl(PR_SET_CHILD_SUBREAPER, 1)) {
if (errno == EINVAL) {
PRINT_FATAL("PR_SET_CHILD_SUBREAPER はこのプラットフォームでは利用できません。Linux >= 3.4 を使用していますか?")
} else {
PRINT_FATAL("子サブリーパーとして登録に失敗しました: %s", strerror(errno))
}
return 1;
} else {
PRINT_TRACE("子サブリーパーとして登録されました");
}
}
return 0;
}
int wait_and_forward_signal(sigset_t const* const parent_sigset_ptr, pid_t const child_pid) {
siginfo_t sig;
if (sigtimedwait(parent_sigset_ptr, &sig, &ts) == -1) {
switch (errno) {
case EAGAIN:
break;
case EINTR:
break;
default:
PRINT_FATAL("sigtimedwait で予期しないエラーが発生しました: '%s'", strerror(errno));
return 1;
}
} else {
/* ここで処理すべき信号があります */
switch (sig.si_signo) {
case SIGCHLD:
/* 特別に扱います。SIGCHLD は転送しません。代わりに、プロセスを回収します。 */
PRINT_DEBUG("SIGCHLD を受信しました");
break;
default:
PRINT_DEBUG("信号を転送します: '%s'", strsignal(sig.si_signo));
/* 他の信号を転送します */
if (kill(kill_process_group ? -child_pid : child_pid, sig.si_signo)) {
if (errno == ESRCH) {
PRINT_WARNING("子プロセスは信号転送時に死亡していました");
} else {
PRINT_FATAL("信号転送時に予期しないエラーが発生しました: '%s'", strerror(errno));
return 1;
}
}
break;
}
}
return 0;
}
ここで、2 つのコアポイントが明確に示されています。
- tini は prctl と PR_SET_CHILD_SUBREAPER を使用して、コンテナ内の孤児プロセスを引き受けます。
- tini は信号を受信した後、子プロセスまたはその所属する子プロセスグループに信号を転送します。
もちろん、tini 自体にもいくつかの小さな問題があります(ただし、あまり一般的ではありません)。ここでディスカッションのための問題を残しておきます。例えば、10 個のデーモンプログラムを作成した後に自分自身が終了するサービスがあるとします。この 10 個のデーモンプログラムの中で、全く新しいプロセスグループ ID を設定します(いわゆるプロセスグループの逃避)。この場合、どのようにして信号をこれら 10 個のプロセスに転送しますか(議論のために提供します。実際の運用でこれを行う人は早々に叩かれるでしょう)。
まとめ#
ここまで読んでいただいた方の中には、私が武道を語らずに、コンテナ内の 1 号プロセスについて話すと言っておきながら、Linux プロセスについての話が大半を占めていることに不満を持つ方もいるかもしれません。
実際、従来のコンテナは OS 内で実行される完全なプロセスと見なすことができます。コンテナ内の 1 号プロセスについて議論するには、Linux におけるプロセス管理に関する知識を欠かすことはできません。
この技術的な水文が、コンテナ内の 1 号プロセスについての大まかな理解を助け、正しく使用し管理できるようになることを願っています。
最後に、皆さんの新年が素晴らしいものでありますように!(新年には水文を書く生活から解放されたいです、ううううう)
参考文献#
- [1]. Docker
- [2]. containerd
- [3]. kata
- [4]. task_struct
- [5]. Linux Man Page: fork
- [9]. tini